In the previous blogs, we explored:
Why Do We Need Vector Embeddings?
Imagine you’re in a giant library with millions of books (like the internet).
If someone asks,
“Show me books about healthy Indian recipes,”
you don’t start reading every single page.
Instead, you look at the index and quickly find relevant sections.
For LLMs, vector embeddings act like that index.
They convert words, sentences, or documents into numbers—points in a high-dimensional space—so the AI can search and match meaning instead of just matching exact words.
What Exactly Is a Vector Embedding?
A vector embedding is just a list of numbers that represents the meaning of a word, sentence, or document.
For example, suppose we have three words:
| Word | Vector Representation (Example) |
|---|---|
| “king” | [0.8, 0.1, 0.5] |
| “queen” | [0.79, 0.12, 0.47] |
| “apple” | [0.05, 0.9, 0.2] |
- “king” and “queen” have similar vectors → similar meanings.
- “apple” is far away → different meaning.
This helps LLMs understand context.
When you ask “Who is the queen of England?”, embeddings allow the LLM to relate concepts like queen, kingdom, and royalty without relying only on keyword matching.
A Simple Example
Let’s take a real-world example.
Scenario
You have three short sentences:
- “I love eating apples”
- “Oranges are my favorite”
- “The king rules the kingdom”
Convert Sentences into Embeddings
We’ll use a small Python example to generate sentence embeddings.
from sentence_transformers import SentenceTransformer
import numpy as np
sentences = [
"I love eating apples",
"Oranges are my favorite",
"The king rules the kingdom"
]
model = SentenceTransformer("all-MiniLM-L6-v2")
# Unit-normalize for true cosine via dot product
embeddings = model.encode(sentences, normalize_embeddings=True)
# Cosine similarity = dot product for unit vectors
similarities = embeddings @ embeddings.T
# Clean tiny FP noise
similarities = np.clip(similarities, -1.0, 1.0)
print(np.round(similarities, 3))Expected Output
[[1. 0.462 0.136]
[0.462 1. 0.139]
[0.136 0.139 1. ]]
In use if you want to use nomic-embed-text from Ollama, run this code:
# Requires: pip install ollama numpy
# And ensure the Ollama daemon is running: `ollama serve`
# First time only: `ollama pull nomic-embed-text`
import numpy as np
import ollama
sentences = [
"I love eating apples",
"Oranges are my favorite",
"The king rules the kingdom"
]
def embed_texts_ollama(texts, model="nomic-embed-text"):
"""
Returns a 2D numpy array of embeddings (n_texts x dim)
"""
vectors = []
for t in texts:
resp = ollama.embeddings(model=model, prompt=t)
vectors.append(resp["embedding"])
return np.array(vectors, dtype=np.float32)
# 1) Get embeddings
embeddings = embed_texts_ollama(sentences, model="nomic-embed-text")
# 2) Unit-normalize for true cosine via dot product
norms = np.linalg.norm(embeddings, axis=1, keepdims=True)
embeddings_unit = embeddings / np.clip(norms, 1e-12, None)
# 3) Cosine similarity matrix = dot product of unit vectors
similarities = embeddings_unit @ embeddings_unit.T
# 4) Clean tiny FP noise for neat printing
similarities = np.clip(similarities, -1.0, 1.0)
print(np.round(similarities, 3))
Expected Output:
[[1. 0.58 0.329]
[0.58 1. 0.352]
[0.329 0.352 1. ]]Most Similar Sentence (Nearest neighbor) for Each Input
from sentence_transformers import SentenceTransformer
import numpy as np
sentences = [
"I love eating apples",
"Oranges are my favorite",
"The king rules the kingdom"
]
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(sentences, normalize_embeddings=True)
# Similarity matrix
similarities = embeddings @ embeddings.T
similarities = np.clip(similarities, -1.0, 1.0)
# Find the nearest neighbor for each sentence
for i, s in enumerate(sentences):
# Ignore self-similarity by setting diagonal to -inf
sims = similarities[i].copy()
sims[i] = -np.inf
j = np.argmax(sims)
print(f"Nearest to {s!r} → {sentences[j]!r} (score: {sims[j]:.3f})")
Expected Output
Nearest to 'I love eating apples' → 'Oranges are my favorite' (score: 0.462)
Nearest to 'Oranges are my favorite' → 'I love eating apples' (score: 0.462)
Nearest to 'The king rules the kingdom' → 'Oranges are my favorite' (score: 0.139)
In case if you want to use nomic-embed-text, run this code:
# pip install ollama numpy
import numpy as np
import ollama
sentences = [
"I love eating apples",
"Oranges are my favorite",
"The king rules the kingdom"
]
def embed_batch(texts, model="nomic-embed-text"):
vecs = []
for t in texts:
r = ollama.embeddings(model=model, prompt=t)
vecs.append(r["embedding"])
return np.array(vecs, dtype=np.float32)
embeddings = embed_batch(sentences)
# L2-normalize so dot product == cosine similarity (like your MiniLM code)
norms = np.linalg.norm(embeddings, axis=1, keepdims=True) + 1e-12
embeddings = embeddings / norms
# Similarity matrix
similarities = embeddings @ embeddings.T
similarities = np.clip(similarities, -1.0, 1.0)
# Nearest neighbor printout
for i, s in enumerate(sentences):
sims = similarities[i].copy()
sims[i] = -np.inf
j = int(np.argmax(sims))
print(f"Nearest to {s!r} → {sentences[j]!r} (score: {sims[j]:.3f})")
Expected Output:
Nearest to 'I love eating apples' → 'Oranges are my favorite' (score: 0.580)
Nearest to 'Oranges are my favorite' → 'I love eating apples' (score: 0.580)
Nearest to 'The king rules the kingdom' → 'Oranges are my favorite' (score: 0.352)This is exactly how embeddings help LLMs find the closest matches.
Let’s build a tiny “semantic search” helper. It builds an index from your existing sentence embeddings and lets you query for the top‑k most similar sentences.
from sentence_transformers import SentenceTransformer
import numpy as np
# ---- Data ----
sentences = [
"I love eating apples",
"Oranges are my favorite",
"The king rules the kingdom"
]
# ---- Model & Corpus Index ----
model = SentenceTransformer("all-MiniLM-L6-v2")
# Normalize so cosine = dot product
embeddings = model.encode(sentences, normalize_embeddings=True)
embeddings = embeddings.astype(np.float32) # smaller & faster
# ---- Search Function ----
def search(query, top_k=3):
"""
Returns a list of (score, sentence, index) sorted by descending similarity.
"""
q_emb = model.encode([query], normalize_embeddings=True).astype(np.float32)[0]
# cosine similarities via dot product (since normalized)
sims = embeddings @ q_emb
# get top-k indices
top_k = min(top_k, len(sentences))
idxs = np.argpartition(-sims, range(top_k))[:top_k]
idxs = idxs[np.argsort(-sims[idxs])] # sort the top-k
return [(float(sims[i]), sentences[i], int(i)) for i in idxs]
# ---- Pretty Printer ----
def show_results(query, top_k=3, min_score=0.3):
results = search(query, top_k=top_k)
print(f"\nQuery: {query!r}")
kept = 0
for rank, (score, text, i) in enumerate(results, 1):
if score >= min_score:
kept += 1
print(f"{rank:>2}. {score:.3f} → {text} [#{i}]")
if kept == 0:
print(f"(no results ≥ {min_score})")
# ---- Examples ----
show_results("I enjoy fruits", top_k=2, min_score=0.3)
show_results("royal authority", top_k=2, min_score=0.3)
Expected Output
Query: 'I enjoy fruits'
1. 0.725 → I love eating apples [#0]
2. 0.568 → Oranges are my favorite [#1]
Query: 'royal authority'
1. 0.557 → The king rules the kingdom [#2]
Why did not it show #1 as part of Query: ‘royal authority’?
Because Oranges are my favorite [#1] → 0.110 which is less than minimum score of 0.3
In case if you want to use nomic-embed-text, run this code:
# pip install ollama numpy
import numpy as np
import ollama
# ---- Data ----
sentences = [
"I love eating apples",
"Oranges are my favorite",
"The king rules the kingdom"
]
EMBED_MODEL = "nomic-embed-text"
def _normalize_rows(mat: np.ndarray) -> np.ndarray:
"""L2-normalize each row so dot product == cosine similarity."""
norms = np.linalg.norm(mat, axis=1, keepdims=True) + 1e-12
return mat / norms
def _embed_texts(texts, model=EMBED_MODEL) -> np.ndarray:
vecs = []
for t in texts:
r = ollama.embeddings(model=model, prompt=t)
vecs.append(r["embedding"])
return np.asarray(vecs, dtype=np.float32)
# ---- Model & Corpus Index ----
embeddings = _embed_texts(sentences)
embeddings = _normalize_rows(embeddings) # cosine = dot
embeddings = embeddings.astype(np.float32) # smaller & faster
# ---- Search Function ----
def search(query, top_k=3):
"""
Returns a list of (score, sentence, index) sorted by descending similarity.
Uses Ollama embeddings; cosine similarity via dot product on normalized vectors.
"""
q_emb = _embed_texts([query])[0].astype(np.float32)
q_emb = q_emb / (np.linalg.norm(q_emb) + 1e-12)
# cosine similarities via dot product (since normalized)
sims = embeddings @ q_emb # shape: (N,)
# get top-k indices
top_k = min(top_k, len(sentences))
idxs = np.argpartition(-sims, range(top_k))[:top_k]
idxs = idxs[np.argsort(-sims[idxs])] # sort the top-k
return [(float(sims[i]), sentences[i], int(i)) for i in idxs]
# ---- Pretty Printer ----
def show_results(query, top_k=3, min_score=0.3):
results = search(query, top_k=top_k)
print(f"\nQuery: {query!r}")
kept = 0
for rank, (score, text, i) in enumerate(results, 1):
if score >= min_score:
kept += 1
print(f"{rank:>2}. {score:.3f} → {text} [#{i}]")
if kept == 0:
print(f"(no results ≥ {min_score})")
# ---- Examples ----
show_results("I enjoy fruits", top_k=2, min_score=0.3)
show_results("royal authority", top_k=2, min_score=0.3)
Expected Output:
Query: 'I enjoy fruits'
1. 0.729 → I love eating apples [#0]
2. 0.688 → Oranges are my favorite [#1]
Query: 'royal authority'
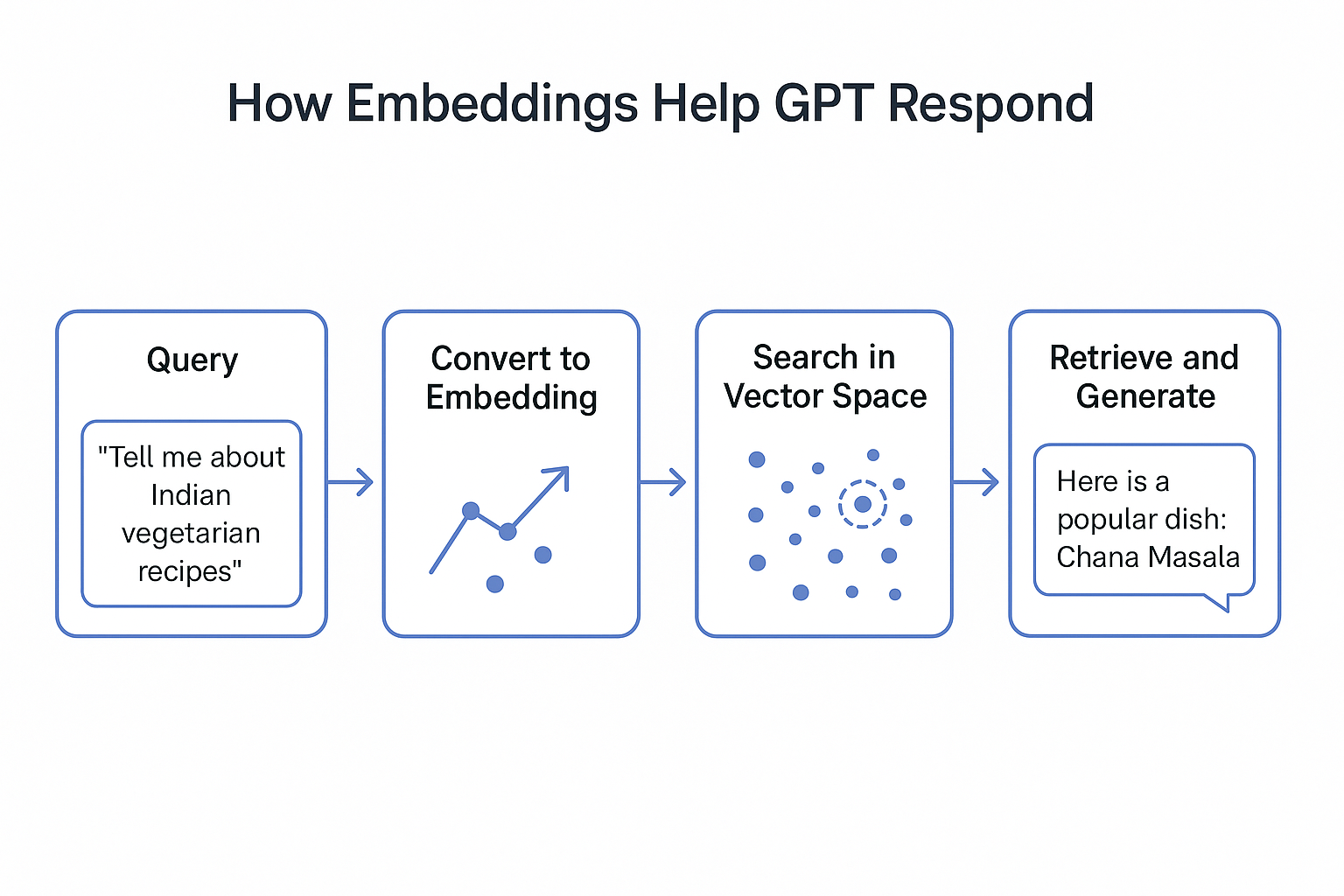
1. 0.664 → The king rules the kingdom [#2]How Embeddings Help LLMs Respond
When you ask GPT something like:
“Tell me about Indian vegetarian recipes,”
Here’s what happens behind the scenes:
- Your query → Converted into a vector embedding.
- The LLM compares your vector with stored document embeddings.
- It retrieves the most relevant content.
- GPT then generates a response using that content + its knowledge.
This process is called Semantic Search—the AI finds meaning, not just exact words.
Visualizing It Simply
Imagine a map 🗺️:
- Each dot on the map = one sentence/document.
- Dots closer together → similar meaning.
- GPT finds the cluster closest to your question and uses that information to reply.
Without embeddings, GPT would have to search through raw text every time, making responses slower and less accurate.
Key Takeaways
- Embeddings convert words/sentences into vectors → numbers that represent meaning.
- They allow LLMs to find related information quickly.
- They make GPTs smarter at understanding context and intent.
- Without embeddings, GPTs would be less efficient and less accurate.
