“Attention Is All You Need” (Vaswani et al., 2017) is the landmark paper that introduced the Transformer architecture, which is the backbone of all modern LLMs (GPT, BERT, LLaMA, etc.). Imagine you’re reading a story: “The dog chased the ball because it was fast.” Now, what does “it” refer to? As humans, we instantly know “it” = the ball.We do …
How are token IDs generated for tokens? So the algorithm is basically: Is there a universal algorithm? No — different models use different tokenization algorithms: 👉 This means token IDs are not universal. “hello” might be 31373 in GPT-2 but a completely different number in LLaMA. Does each embedding model have its own tokenizer? Yes. Every embedding model comes with: If you mix and match (e.g., GPT …
In our previous blogs, we learned: Now, let’s take the next step and explore RAG (Retrieval-Augmented Generation) — the technique powering modern AI chatbots, search engines, and intelligent assistants. Why Do We Need RAG? Large Language Models (LLMs) like GPT are trained on massive datasets but still have limitations: Without RAG You ask GPT:“What’s the latest Azure …
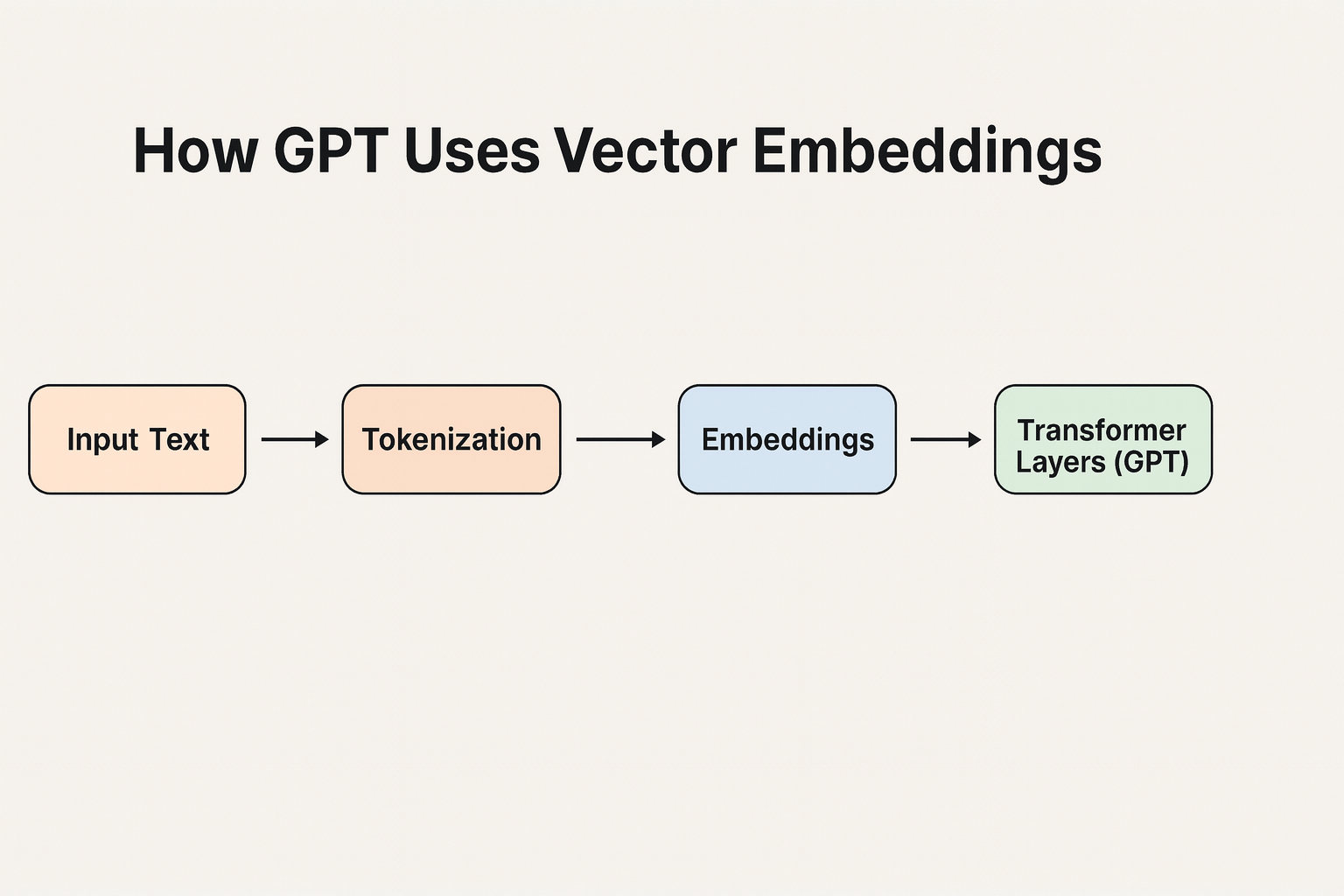
A Quick Recap From the tokenization blog, we know: For example, using GPT’s tokenizer: Word Token Token ID “I” I 1464 “love” love 3672 “apples” apples 9221 So, your sentence:“I love apples” → [1464, 3672, 9221] These token IDs are just numbers — but at this stage, GPT still doesn’t know their meaning.That’s where embeddings come in. Token IDs → Embeddings A token embedding …
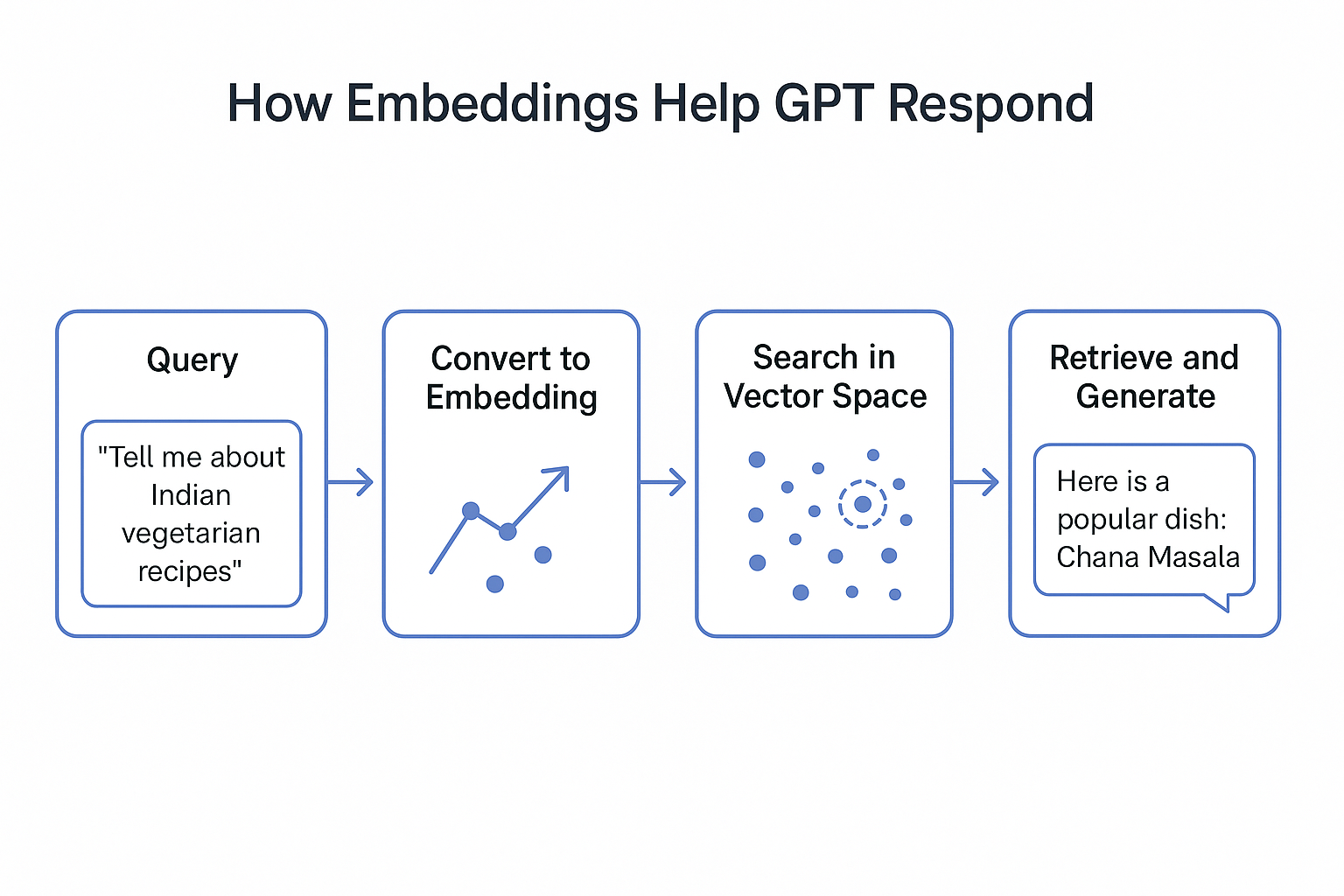
In the previous blogs, we explored: Why Do We Need Vector Embeddings? Imagine you’re in a giant library with millions of books (like the internet).If someone asks, “Show me books about healthy Indian recipes,”you don’t start reading every single page.Instead, you look at the index and quickly find relevant sections. For LLMs, vector embeddings act like that index.They convert words, sentences, or documents into numbers—points in …
Large Language Models (LLMs) like GPT-4, or open-source models such as Mistral, have unlocked incredible ways to generate text, solve problems, and even reason with complex queries. But to make use of their true power, we need to learn the art of prompt engineering. In this post, I will go through: Thanks to Hugging Face’s …
The loss function is how LLMs learn in the first place At the heart of every machine learning model, from simple linear regression to massive LLMs like GPT-4, is a loss function.It measures how wrong the model’s predictions are. For language models, the most common loss function is cross-entropy loss, which measures how well the model’s predicted probability distribution …
How does a machine learning model know that if it is performing well or not? It needs a way to measure how far off its predictions are from reality. That’s where the loss function comes in. Think of the loss function as the model’s internal GPS telling it, “You’re this far away from your destination—time to adjust!” Simple …
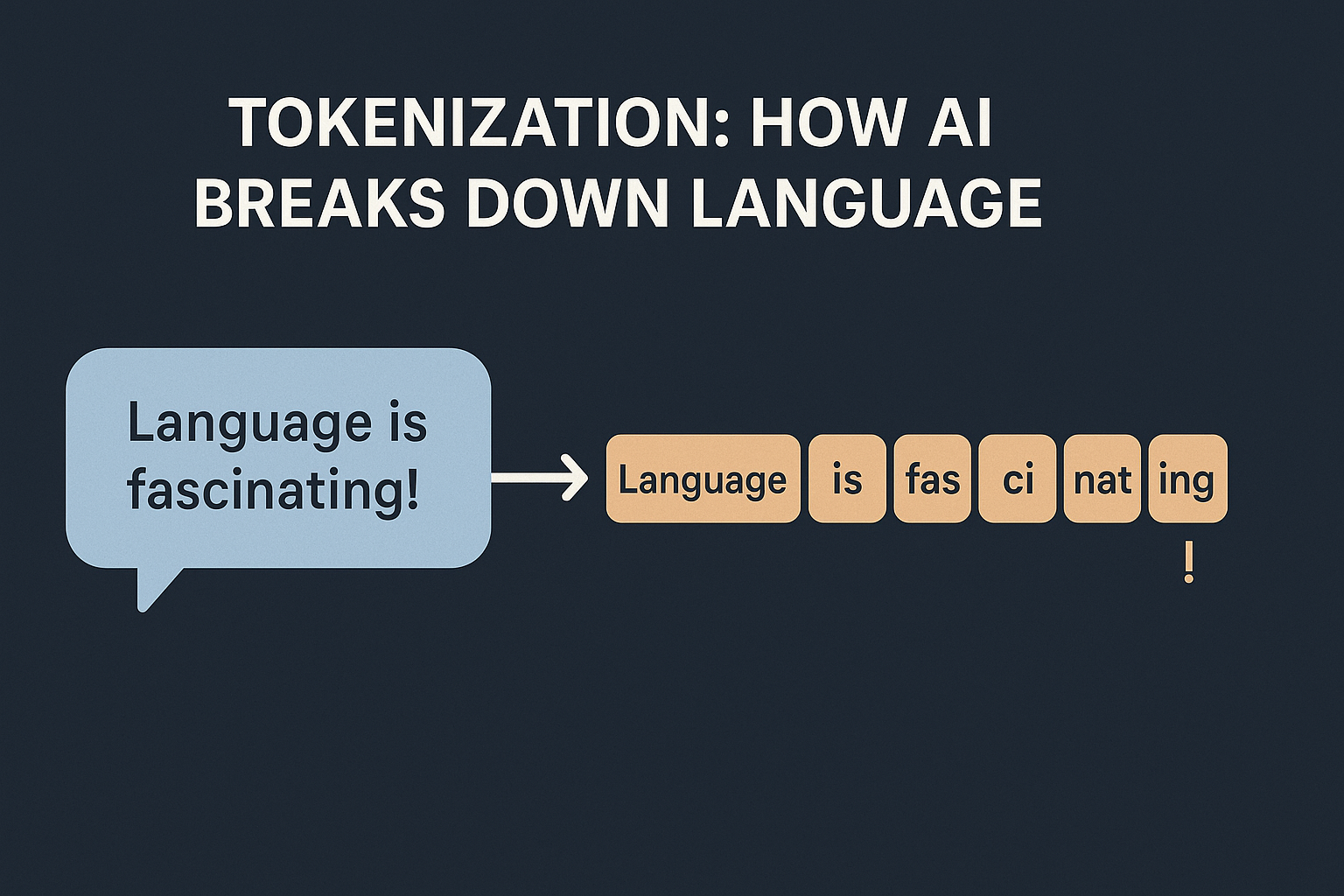
I am assuming the audience for this blog is programmers who may or may not have exposure to AI. Whenever we discuss about LLMs, we often hear the term “Tokenization“. In AI, it simply means how models break text into smaller pieces. Why can’t we just feed text to an AI? Machines don’t work with …
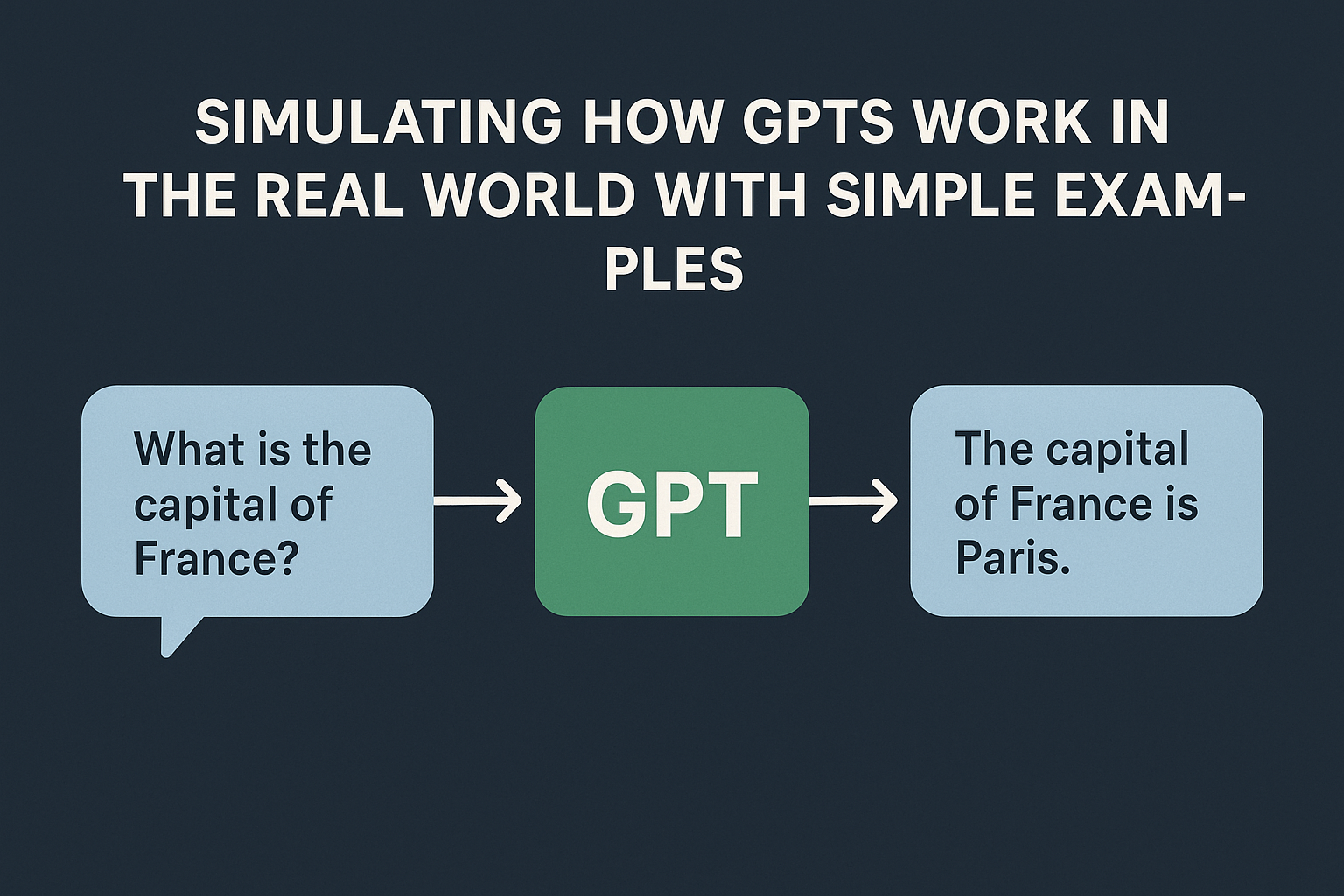
Have you ever wondered: I’ll take you on a simple, intuitive journey, building a tiny version of GPT from scratch that does exactly this — so you can walk away knowing precisely how it all works under the hood. We’ll do this by: How GPTs Learn and Store Knowledge Let’s start simple. Imagine you’re learning a new language. You …