In our previous blogs, we learned:
- Simulating How GPTs Work
- Tokenization – How AI Breaks Down Language
- Vector Embeddings – How They Help GPT Understand and Respond
Now, let’s take the next step and explore RAG (Retrieval-Augmented Generation) — the technique powering modern AI chatbots, search engines, and intelligent assistants.
Why Do We Need RAG?
Large Language Models (LLMs) like GPT are trained on massive datasets but still have limitations:
- Knowledge Cutoff → GPT can’t know anything after its training date.
- Private Data Access → It can’t read your company documents or APIs by default.
- Fresh Information → It can’t fetch the latest updates unless connected to external sources.
Without RAG
You ask GPT:
“What’s the latest Azure AI pricing?”
- GPT responds based on its training data, which may be outdated.
With RAG
- GPT converts your question into embeddings.
- Searches a vector database for the most relevant documents.
- Retrieves fresh, private, or domain-specific knowledge.
- Combines that context with its reasoning to generate an accurate answer.
RAG = GPT’s intelligence + real-time knowledge
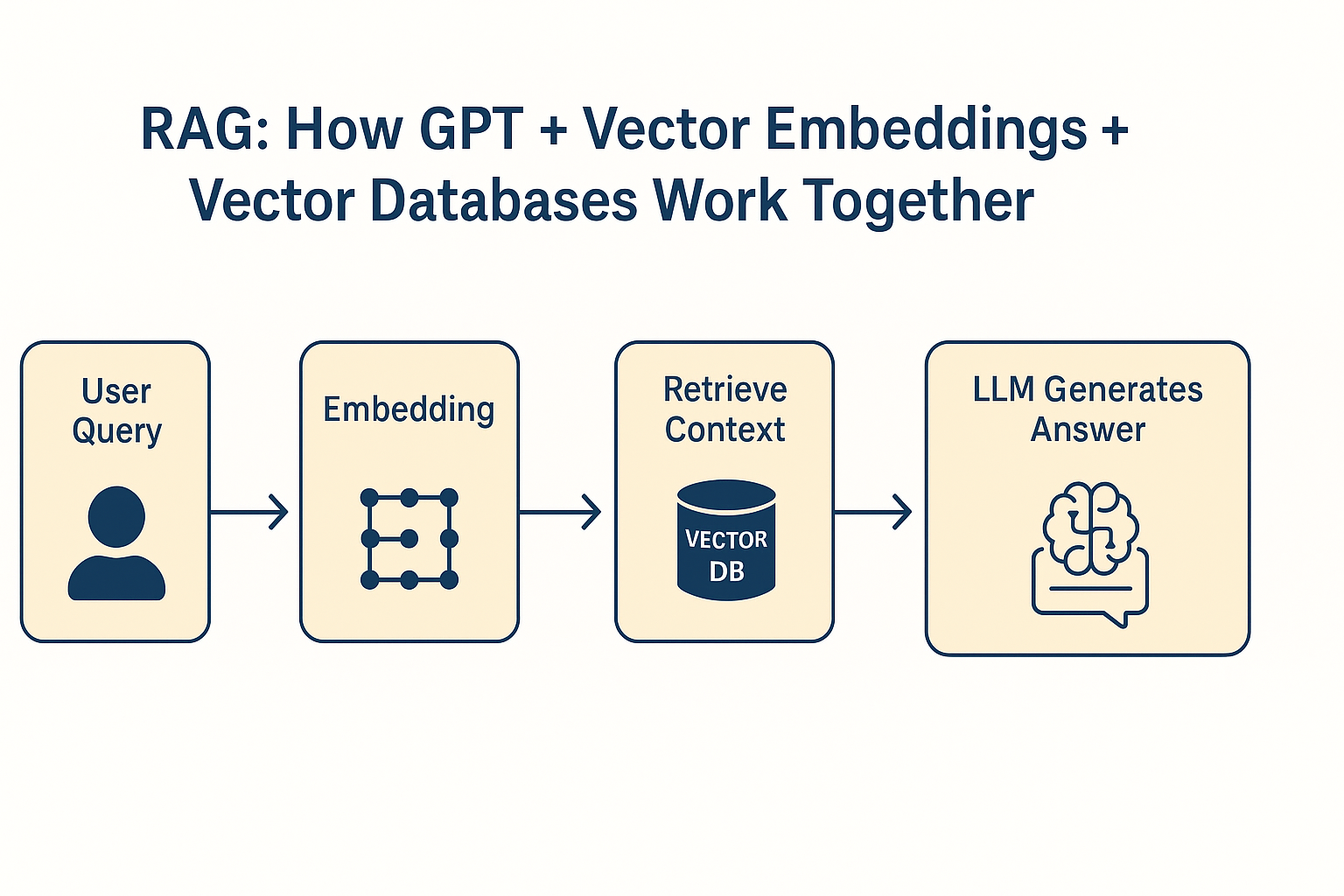
How RAG Works
RAG combines three key components:
| Component | Role in RAG | Examples |
|---|---|---|
| LLM | Understands queries & generates responses | GPT, Claude, Gemini |
| Vector Embeddings | Convert text into numerical meaning | Sentence Transformers, OpenAI embeddings |
| Vector Database | Stores & retrieves embeddings quickly | Chroma, Pinecone, Weaviate, FAISS |
Step-by-Step Workflow
Let’s say a user asks:
“Show me Azure AI pricing updates from this week.”
- Convert Query to Embeddings → Transform the query into a vector representing its meaning.
- Vector Search → Compare this embedding with stored document embeddings.
- Retrieve Context → Fetch relevant information.
- GPT Generates Answer → Combine retrieved context + GPT’s reasoning → accurate response.
RAG Architecture Diagram
A Practical Example in Python
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# Step 1 — Create Embeddings for Documents
model = SentenceTransformer('all-MiniLM-L6-v2')
docs = [
"Azure AI pricing updated on Aug 2025: $0.001 per token",
"AWS AI pricing July 2025: $0.002 per token",
"Google AI pricing May 2025: $0.0015 per token"
]
doc_embeddings = model.encode(docs)
# Step 2 — Store in Vector Database (FAISS)
dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(np.array(doc_embeddings))
# Step 3 — Search for Relevant Docs
query = "Azure AI pricing updates"
query_embedding = model.encode([query])
distances, indices = index.search(np.array(query_embedding), k=1)
# Step 4 — Retrieve Top Match
print("Best Match:", docs[indices[0][0]])Expected Output
Best Match: Azure AI pricing updated on Aug 2025: $0.001 per token
In case if you want to use ChromaDb with Ollama, run this code:
# chroma_ollama_demo.py
# Uses ChromaDB + Ollama embeddings
import numpy as np
import ollama
import chromadb
from chromadb.config import Settings
EMBED_MODEL = "nomic-embed-text" # 2048-dim, local via Ollama
PERSIST_DIR = "./chroma_store" # set to a folder path (e.g. "./chroma_store") to persist between runs
# --- Custom embedding function for ChromaDB ---
class OllamaEmbeddingFunction:
def __init__(self, model: str = EMBED_MODEL):
self.model = model
def __call__(self, input: list[str]) -> list[list[float]]:
# Chroma will pass a list[str]; return list of vectors (list[list[float]])
vectors = []
for t in input:
r = ollama.embeddings(model=self.model, prompt=t)
vectors.append(r["embedding"])
return vectors
# --- Initialize ChromaDB client & collection ---
client = chromadb.Client(Settings(
anonymized_telemetry=False,
persist_directory=PERSIST_DIR # set a path to persist; None = in-memory
))
COLLECTION_NAME = "pricing_demo"
# Clean up any stale collection for idempotent runs (optional)
try:
client.delete_collection(COLLECTION_NAME)
except Exception:
pass
collection = client.create_collection(
name=COLLECTION_NAME,
embedding_function=OllamaEmbeddingFunction(EMBED_MODEL),
metadata={"hnsw:space": "cosine"} # ensure cosine distance (recommended for embeddings)
)
# --- Step 1: Add documents (Chroma will call our embedder) ---
docs = [
"Azure AI pricing updated on Aug 2025: $0.001 per token",
"AWS AI pricing July 2025: $0.002 per token",
"Google AI pricing May 2025: $0.0015 per token"
]
ids = [f"doc-{i}" for i in range(len(docs))]
metadatas = [{"source": "demo", "vendor": v.split()[0]} for v in docs]
collection.add(
ids=ids,
documents=docs,
metadatas=metadatas
)
# --- Step 2/3: Query for the most relevant documents ---
query = "Azure AI pricing updates"
results = collection.query(
query_texts=[query],
n_results=1,
include=["documents", "metadatas", "distances"]
)
best_doc = results["documents"][0][0]
best_dist = results["distances"][0][0] # cosine distance (lower is better)
best_meta = results["metadatas"][0][0]
print(f"Query: {query!r}")
print(f"Best Match: {best_doc}")
print(f"Distance: {best_dist:.4f} (cosine distance; lower = closer)")
print(f"Metadata: {best_meta}")
Expected Output:
Query: 'Azure AI pricing updates'
Best Match: Azure AI pricing updated on Aug 2025: $0.001 per token
Distance: 0.1549 (cosine distance; lower = closer)
Metadata: {'source': 'demo', 'vendor': 'Azure'}If you want to extend the above code with another example, here is the code which shows how the LLM responds with strict mode ON:
# rag_ollama_chroma.py
# Local RAG pipeline with an "I don't know" guardrail + fallback to retrieval
import ollama
import chromadb
import numpy as np
from chromadb.config import Settings
from typing import List, Dict, Any, Optional
import os
os.environ["CHROMA_TELEMETRY_DISABLED"] = "1"
# ======== CONFIG ========
LLM_MODEL = "llama3.1:8b" # or "mistral:latest"
EMBED_MODEL = "nomic-embed-text" # local embedding model via Ollama
PERSIST_DIR = "./chroma_store" # set to None for in-memory
COLLECTION_NAME = "ai_pricing_demo"
# RAG knobs
TOP_K = 3 # how many chunks to retrieve
MAX_CHUNK_TOKENS = 200 # crude chunk size (characters-based for simplicity here)
MIN_SIMILARITY = 0.25 # if using cosine similarity (we'll request distances and convert)
STRICT_IDK = True # the model must say exactly: "I don't know." when uncertain
# ======== Embedding function for Chroma ========
class OllamaEmbeddingFunction:
def __init__(self, model: str = EMBED_MODEL):
self.model = model
def __call__(self, input: List[str]) -> List[List[float]]:
vecs = []
for t in input:
r = ollama.embeddings(model=self.model, prompt=t)
vecs.append(r["embedding"])
return vecs
# ======== LLM helpers ========
SYSTEM_PROMPT_BASE = f"""
You are a careful AI assistant. If you are NOT reasonably confident in an answer OR the answer is not present in the user's provided context, you MUST respond with exactly:
I don't know.
- Do not guess.
- If you do answer, be concise and factual.
"""
def llm_answer(prompt: str, system: Optional[str] = None) -> str:
"""Ask the LLM directly with an 'I don't know' guardrail."""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
res = ollama.chat(model=LLM_MODEL, messages=messages)
return res["message"]["content"].strip()
def llm_with_context(question: str, context_docs: List[str]) -> str:
"""Ask the LLM but constrain it to the retrieved context."""
context_block = "\n\n".join(f"- {d}" for d in context_docs)
prompt = f"""Answer the question using ONLY the context below.
If the context does not contain the answer, reply exactly:
I don't know.
Context:
{context_block}
Question: {question}
"""
return llm_answer(prompt, system=SYSTEM_PROMPT_BASE)
# ======== Chroma setup ========
def get_chroma_collection(name: str = COLLECTION_NAME, persist_dir: Optional[str] = PERSIST_DIR):
client = chromadb.Client(Settings(
anonymized_telemetry=False,
persist_directory=persist_dir
))
# re-use if exists, else create
try:
col = client.get_collection(name)
except Exception:
col = client.create_collection(
name=name,
embedding_function=OllamaEmbeddingFunction(EMBED_MODEL),
metadata={"hnsw:space": "cosine"} # cosine distance
)
return col
# ======== Simple chunking (character-based for demo) ========
def chunk_text(text: str, max_chars: int = 800) -> List[str]:
text = text.strip()
if len(text) <= max_chars:
return [text]
chunks = []
i = 0
while i < len(text):
chunks.append(text[i:i+max_chars])
i += max_chars
return chunks
# ======== Ingest documents into Chroma ========
def ingest_documents(collection, docs: List[str], metadatas: Optional[List[Dict[str, Any]]] = None):
# Flatten into chunks
ids = []
chunk_docs = []
chunk_metas = []
for i, d in enumerate(docs):
chunks = chunk_text(d, max_chars=MAX_CHUNK_TOKENS*4) # heuristic conversion
for j, ch in enumerate(chunks):
ids.append(f"doc-{i}-chunk-{j}")
chunk_docs.append(ch)
md = {"doc_index": i, "chunk_index": j}
if metadatas and i < len(metadatas):
md.update(metadatas[i])
chunk_metas.append(md)
# Upsert
collection.upsert(
ids=ids,
documents=chunk_docs,
metadatas=chunk_metas
)
return len(ids)
# ======== Retrieval ========
def retrieve(collection, query: str, k: int = TOP_K) -> Dict[str, Any]:
"""
Returns Chroma query results. Distances are cosine distances (lower=closer).
We'll compute similarity = 1 - distance for readability.
"""
results = collection.query(
query_texts=[query],
n_results=k,
include=["documents", "metadatas", "distances"]
)
docs = results.get("documents", [[]])[0]
metas = results.get("metadatas", [[]])[0]
dists = results.get("distances", [[]])[0]
sims = [1.0 - float(d) for d in dists] # cosine similarity
return {"docs": docs, "metadatas": metas, "similarities": sims}
# ======== Orchestrator ========
def answer_question(question: str, collection) -> str:
"""
1) Ask LLM directly (guardrailed). If it knows, return the answer unless it's "I don't know."
2) If "I don't know.", do retrieval from Chroma and ask LLM again with context.
3) If retrieval weak or LLM still "I don't know.", return "I don't know."
"""
# Step 1: direct ask
direct = llm_answer(
prompt=f"Question: {question}\nProvide an accurate answer if you are reasonably sure.",
system=SYSTEM_PROMPT_BASE
)
if direct.strip().lower() != "i don't know.":
return direct # model felt confident
# Step 2: RAG fallback
r = retrieve(collection, question, k=TOP_K)
# Filter by similarity threshold
paired = [(doc, sim) for doc, sim in zip(r["docs"], r["similarities"]) if sim >= MIN_SIMILARITY]
if not paired:
return "I don't know."
context_docs = [d for d, _ in paired]
rag_answer = llm_with_context(question, context_docs).strip()
return rag_answer
# ======== Demo ========
if __name__ == "__main__":
# Example small domain: pricing snippets
docs = [
"Azure AI pricing updated on Aug 2025: $0.001 per token",
"AWS AI pricing July 2025: $0.002 per token",
"Google AI pricing May 2025: $0.0015 per token"
]
metadatas = [
{"vendor": "Azure"},
{"vendor": "AWS"},
{"vendor": "Google"}
]
collection = get_chroma_collection()
# Optional: clear existing and re-ingest for a clean demo
try:
# If you want a clean state each run, drop and recreate:
client = chromadb.Client(Settings(persist_directory=PERSIST_DIR, anonymized_telemetry=False))
client.delete_collection(COLLECTION_NAME)
collection = client.create_collection(
name=COLLECTION_NAME,
embedding_function=OllamaEmbeddingFunction(EMBED_MODEL),
metadata={"hnsw:space": "cosine"}
)
except Exception:
pass
num_chunks = ingest_documents(collection, docs, metadatas)
print(f"Ingested {num_chunks} chunks.\n")
# 1) A question likely unknown to general LLM but in our RAG docs:
q1 = "What is the latest Azure AI pricing update?"
print("Q1:", q1)
a1 = answer_question(q1, collection)
print("A1:", a1, "\n")
# 2) A question the base LLM may answer by itself (no RAG needed):
q2 = "What is the capital of France?"
print("Q2:", q2)
a2 = answer_question(q2, collection)
print("A2:", a2, "\n")
# 3) A question neither LLM nor RAG can answer (should return 'I don't know.'):
q3 = "What is the square root of the CEO of Azure?"
print("Q3:", q3)
a3 = answer_question(q3, collection)
print("A3:", a3, "\n")
Expected Output:
Q1: What is the latest Azure AI pricing update?
A1: I don't know. The information might be outdated or I'm not aware of a recent update specific to Azure AI pricing. For the most accurate and up-to-date information, I recommend checking Microsoft's official Azure website or contacting their support directly.
Q2: What is the capital of France?
A2: Paris.
Q3: What is the square root of the CEO of Azure?
Failed to send telemetry event CollectionQueryEvent: capture() takes 1 positional argument but 3 were given
A3: I don't know. Improvised code with more guardrails:
# rag_ollama_chroma2.py
# Local RAG pipeline with an "I don't know" guardrail + fallback to retrieval
# Shows which path answered (LLM vs RAG vs IDK) and prints retrieved context.
import os
os.environ["CHROMA_TELEMETRY_DISABLED"] = "1"
import ollama
import chromadb
import numpy as np
from chromadb.config import Settings
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
# ---- ChromaDB + Ollama Embedding Setup ----
EMBED_MODEL = "nomic-embed-text"
COLLECTION_NAME = "ai_pricing_demo"
PERSIST_DIR = "./chroma_store"
class OllamaEmbeddingFunction:
def __init__(self, model: str = EMBED_MODEL):
self.model = model
def __call__(self, input: List[str]) -> List[List[float]]:
vecs = []
for t in input:
r = ollama.embeddings(model=self.model, prompt=t)
vecs.append(r["embedding"])
return vecs
def get_chroma_collection(name: str = COLLECTION_NAME, persist_dir: Optional[str] = PERSIST_DIR):
client = chromadb.Client(Settings(
anonymized_telemetry=False,
persist_directory=persist_dir
))
# re-use if exists, else create
try:
col = client.get_collection(name)
except Exception:
col = client.create_collection(
name=name,
embedding_function=OllamaEmbeddingFunction(EMBED_MODEL),
metadata={"hnsw:space": "cosine"} # cosine distance
)
return col
MAX_CHUNK_TOKENS = 200 # crude chunk size (characters-based for simplicity here)
def chunk_text(text: str, max_chars: int = 800) -> List[str]:
text = text.strip()
if len(text) <= max_chars:
return [text]
chunks = []
i = 0
while i < len(text):
chunks.append(text[i:i+max_chars])
i += max_chars
return chunks
def ingest_documents(collection, docs: List[str], metadatas: Optional[List[Dict[str, Any]]] = None):
# Flatten into chunks
ids = []
chunk_docs = []
chunk_metas = []
for i, d in enumerate(docs):
chunks = chunk_text(d, max_chars=MAX_CHUNK_TOKENS*4) # heuristic conversion
for j, ch in enumerate(chunks):
ids.append(f"doc-{i}-chunk-{j}")
chunk_docs.append(ch)
md = {"doc_index": i, "chunk_index": j}
if metadatas and i < len(metadatas):
md.update(metadatas[i])
chunk_metas.append(md)
# Upsert
collection.upsert(
ids=ids,
documents=chunk_docs,
metadatas=chunk_metas
)
# ---- LLM ----
LLM_MODEL = "llama3.1:8b" # or "mistral:latest"
SYSTEM_PROMPT_BASE = """
You are a strict assistant.
RULES:
- If you are NOT 100% certain or the information is not in the provided context,
you MUST answer exactly: I don't know.
- Do not provide general advice, links, guesses, or background info.
- Never try to be helpful when unsure.
- If you know, respond concisely and factually.
Example:
Q: What is the square root of the CEO of Azure?
A: I don't know.
""".strip()
def enforce_idk(text: str) -> str:
lowered = text.lower()
if "i don't know" in lowered or "i dont know" in lowered:
return "I don't know."
# if it rambles but didn’t follow rule, treat as IDK
if "http" in lowered or "cannot provide" in lowered or "not aware" in lowered:
return "I don't know."
return text.strip()
def llm_answer(prompt: str, system: Optional[str] = SYSTEM_PROMPT_BASE) -> str:
"""Ask the LLM directly with an 'I don't know' guardrail."""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
res = ollama.chat(model=LLM_MODEL, messages=messages)
return enforce_idk(res["message"]["content"])
def llm_with_context(question: str, context_docs: List[str]) -> str:
"""Ask the LLM but constrain it to the retrieved context."""
context_block = "\n\n".join(f"- {d}" for d in context_docs)
prompt = f"""Answer the question using ONLY the context below.
If the context does not contain the answer, reply exactly:
I don't know.
Context:
{context_block}
Question: {question}
"""
return llm_answer(prompt, system=SYSTEM_PROMPT_BASE)
# ---- Retrieval ----
TOP_K = 3 # how many chunks to retrieve
MIN_SIMILARITY = 0.25 # cosine similarity threshold for retrieval (1 - distance)
def retrieve(collection, query: str, k: int = TOP_K) -> Dict[str, Any]:
"""
Returns Chroma query results. Distances are cosine distances (lower=closer).
We'll compute similarity = 1 - distance for readability.
"""
results = collection.query(
query_texts=[query],
n_results=k,
include=["documents", "metadatas", "distances"]
)
docs = results.get("documents", [[]])[0]
metas = results.get("metadatas", [[]])[0]
dists = results.get("distances", [[]])[0]
sims = [1.0 - float(d) for d in dists] # cosine similarity
return {"docs": docs, "metadatas": metas, "similarities": sims}
# ---- Result container ----
@dataclass
class AnswerResult:
text: str
source: str # "LLM", "RAG", or "IDK"
retrieved: Optional[List[str]] = None
similarities: Optional[List[float]] = None
# ---- Orchestrator ----
def answer_question(question: str, collection, prefer_direct: bool = True) -> AnswerResult:
"""
prefer_direct=True:
1) Ask LLM directly (guardrailed to say "I don't know." if unsure)
2) If "I don't know.", do RAG (Chroma) and ask with context
3) If retrieval weak or still unknown, return "I don't know." (source="IDK")
prefer_direct=False:
Do RAG first, then LLM.
"""
def _rag_attempt(q: str) -> AnswerResult:
r = retrieve(collection, q, k=TOP_K)
# keep the raw top-k for transparency
raw_docs = r["docs"]
raw_sims = r["similarities"]
# filter by threshold
paired = [(doc, sim) for doc, sim in zip(raw_docs, raw_sims) if sim >= MIN_SIMILARITY]
if not paired:
return AnswerResult(text="I don't know.", source="IDK", retrieved=raw_docs, similarities=raw_sims)
context_docs = [d for d, _ in paired]
context_sims = [s for _, s in paired]
rag = llm_with_context(q, context_docs).strip()
if rag.lower() == "i don't know.":
return AnswerResult(text=rag, source="IDK", retrieved=context_docs, similarities=context_sims)
return AnswerResult(text=rag, source="RAG", retrieved=context_docs, similarities=context_sims)
if prefer_direct:
direct = llm_answer(f"Question: {question}\nProvide an accurate answer if you are reasonably sure.")
if direct.lower() != "i don't know.":
return AnswerResult(text=direct, source="LLM")
return _rag_attempt(question)
else:
rag_res = _rag_attempt(question)
if rag_res.source == "RAG":
return rag_res
direct = llm_answer(f"Question: {question}\nProvide an accurate answer if you are reasonably sure.")
if direct.lower() != "i don't know.":
return AnswerResult(text=direct, source="LLM")
return AnswerResult(text="I don't know.", source="IDK")
# ---- CLI ----
if __name__ == "__main__":
# Example docs to seed the Chroma collection
docs = [
"Azure AI pricing updated on Aug 2025: $0.001 per token",
"AWS AI pricing July 2025: $0.002 per token",
"Google AI pricing May 2025: $0.0015 per token"
]
metadatas = [{"vendor": "Azure"}, {"vendor": "AWS"}, {"vendor": "Google"}]
# Clean & ingest fresh
try:
client = chromadb.Client(Settings(persist_directory=PERSIST_DIR, anonymized_telemetry=False))
client.delete_collection(COLLECTION_NAME)
except Exception:
pass
collection = get_chroma_collection()
ingest_documents(collection, docs, metadatas)
print("🔹 Local RAG Assistant (Ollama + Chroma)")
print("Type your question, or ':quit' to exit.")
print("Commands: ':direct on' → LLM first, ':direct off' → RAG first.")
print(" ':threshold <0..1>' → set min cosine similarity (current: {:.2f})\n".format(MIN_SIMILARITY))
prefer_direct = True
show_topk = True
while True:
q = input("You: ").strip()
if not q:
continue
low = q.lower()
if low in [":quit", ":exit"]:
print("👋 Goodbye!")
break
if low.startswith(":direct"):
if "on" in low:
prefer_direct = True
print("⚙️ Direct-first mode enabled (LLM first, fallback to RAG).")
elif "off" in low:
prefer_direct = False
print("⚙️ RAG-first mode enabled (retrieval first).")
continue
if low.startswith(":threshold"):
try:
_, val = q.split()
valf = float(val)
if 0.0 <= valf <= 1.0:
MIN_SIMILARITY = valf # type: ignore
print(f"⚙️ MIN_SIMILARITY set to {MIN_SIMILARITY:.2f}")
else:
print("Please provide a value between 0 and 1.")
except Exception:
print("Usage: :threshold 0.35")
continue
res = answer_question(q, collection, prefer_direct=prefer_direct)
print(f"Assistant ({res.source}): {res.text}")
if show_topk and res.source in ("RAG", "IDK") and res.retrieved:
print("— Retrieved context (filtered by threshold):")
sims = res.similarities or []
for i, doc in enumerate(res.retrieved):
sim = sims[i] if i < len(sims) else None
if sim is not None:
print(f" {i+1}. sim={sim:.3f} {doc}")
else:
print(f" {i+1}. {doc}")
print()
Expected Output:
You: What is the latest Azure AI pricing update?
Assistant (RAG): $0.001 per token.
— Retrieved context (filtered by threshold):
1. sim=0.850 Azure AI pricing updated on Aug 2025: $0.001 per token
2. sim=0.749 AWS AI pricing July 2025: $0.002 per token
3. sim=0.712 Google AI pricing May 2025: $0.0015 per token
You: What is the capital of France?
Assistant (LLM): Paris.
You: What is the capital of India?
Assistant (LLM): New Delhi.Why RAG Is Powerful
| Traditional GPT | GPT + RAG |
|---|---|
| Stuck with training data | Always up-to-date |
| Can’t access private data | Uses company/internal documents |
| May hallucinate facts | Reduces hallucinations |
| Limited personalization | Enables tailored responses |
Real-World Use Cases
RAG powers modern AI systems everywhere:
- Chatbots → Customer support bots fetching company FAQs.
- Knowledge Assistants → Query internal docs and answer complex queries.
- Search Engines → Use embeddings for semantic search instead of keyword matching.
- Medical & Legal AI → Pull trusted references before generating answers.
If you’ve used ChatGPT with Bing, Perplexity AI, or Claude with Docs, you’ve already experienced RAG in action.
Key Takeaways
- Embeddings convert text into meaningful numbers.
- Vector Databases make searching fast and semantic.
- RAG = GPT + Embeddings + Vector DBs.
- This lets AI reason + retrieve → accurate, up-to-date, and context-aware responses.
