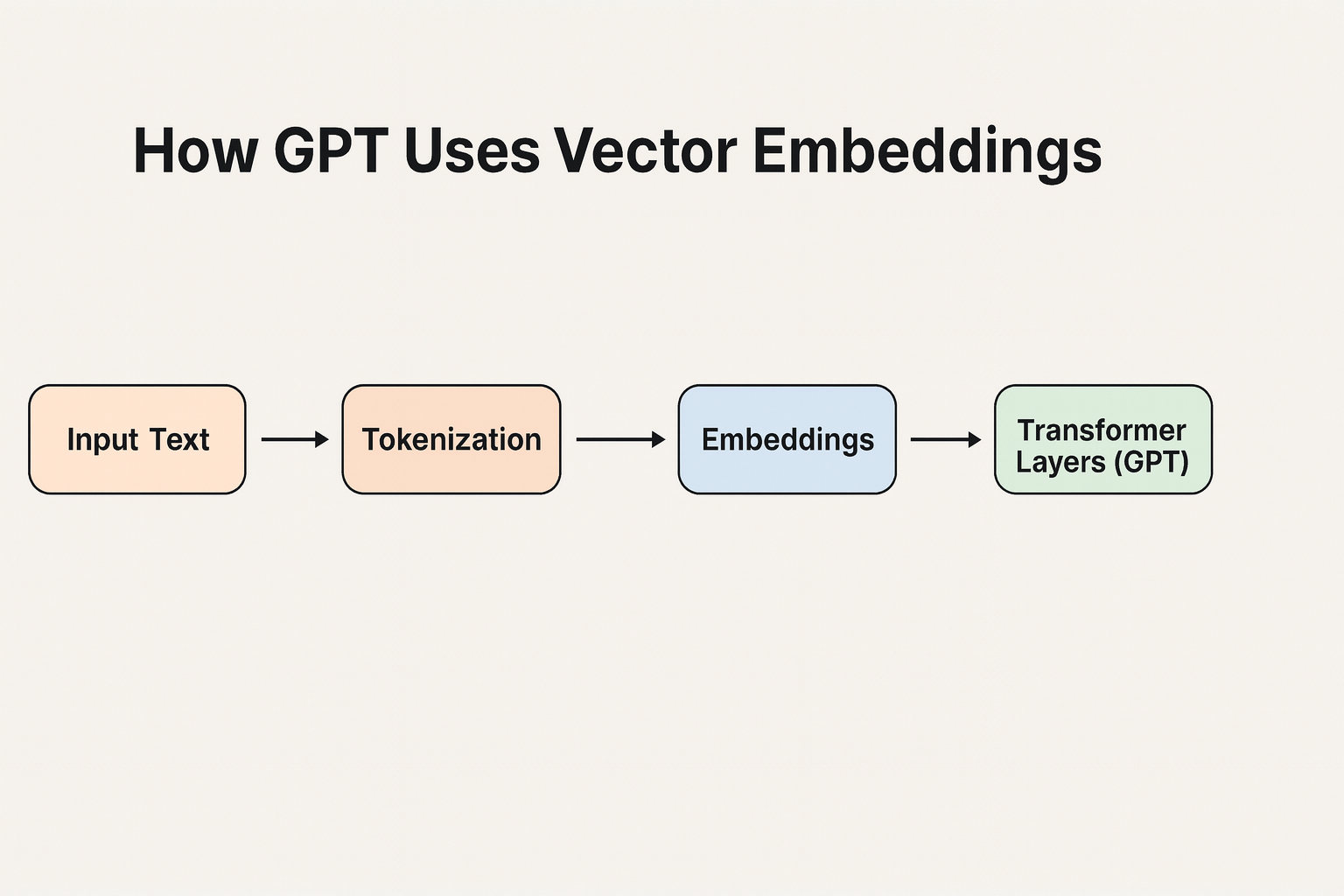
A Quick Recap
From the tokenization blog, we know:
- LLMs don’t understand words directly.
- They break text into tokens → small chunks like words or sub-words.
- Each token is mapped to a unique token ID using the tokenizer’s vocabulary.
For example, using GPT’s tokenizer:
| Word | Token | Token ID |
|---|---|---|
| “I” | I | 1464 |
| “love” | love | 3672 |
| “apples” | apples | 9221 |
So, your sentence:
“I love apples” → [1464, 3672, 9221]
These token IDs are just numbers — but at this stage, GPT still doesn’t know their meaning.
That’s where embeddings come in.
Token IDs → Embeddings
A token embedding layer is the first step inside an LLM.
Its job: Convert token IDs into high-dimensional vectors that represent meaning.
Think of it like this:
Token ID 1464 ("I") → [0.12, -0.32, 0.88, ...]
Token ID 3672 ("love") → [-0.44, 0.76, 0.21, ...]
Token ID 9221 ("apples") → [0.56, 0.11, -0.72, ...]
So, your sentence “I love apples” becomes:
[ [0.12, -0.32, 0.88, ...],
[-0.44, 0.76, 0.21, ...],
[0.56, 0.11, -0.72, ...] ]
These are vector embeddings—mathematical representations of the tokens that encode meaning and context.
Why Not Use Token IDs Directly?
You might ask:
“Why not just feed token IDs into GPT directly?”
Because token IDs are arbitrary.
- Token ID
1464doesn’t mean anything by itself. - Embeddings add semantic meaning: similar words get closer embeddings.
Example:
| Word | Embedding (simplified) |
|---|---|
| “king” | [0.82, 0.15, 0.55] |
| “queen” | [0.81, 0.14, 0.54] |
| “apple” | [0.05, 0.91, 0.20] |
- “king” and “queen” → close together in embedding space.
- “apple” → far away, different meaning.
Without embeddings, GPT couldn’t understand relationships between tokens.
Connecting It All Together
When you ask GPT:
“Tell me about Indian vegetarian recipes.”
Here’s the chain of steps:
- Tokenizer:
"Tell me about Indian vegetarian recipes"→[2112, 65, 342, 1876, 5012, 9983] - Token IDs → Embeddings: Each ID is converted into a vector:
[ [0.22, 0.55, ...], [0.18, -0.09, ...], ... ] - Context Understanding: GPT processes embeddings using attention layers → learns which tokens are related.
- Semantic Matching: If retrieval or vector search is used, embeddings are also matched with external documents for RAG-style responses.
- Response Generation: GPT converts processed embeddings back into token IDs, which are decoded into words.
Putting It All Together
| Stage | Input | Output | Purpose |
|---|
| Tokenization | Text → Tokens | [“I”, “love”, “apples”] | Break into chunks |
| Token IDs | Tokens → Numbers | [1464, 3672, 9221] | Assign unique IDs |
| Embeddings | Token IDs → Vectors | [[0.12,…], [-0.44,…]] | Encode meaning |
| LLM Processing | Embeddings → Context Vectors | Understands relationships | Enables reasoning |
| Response | Context Vectors → Text | “Apples are fruits.” | Generate natural language |
Key Takeaways
- Token IDs are indexes from the tokenizer’s vocabulary.
- Embeddings give meaning to those tokens in a mathematical way.
- LLMs rely on embeddings to:
- Understand context
- Find semantic similarity
- Retrieve relevant information quickly
- Without embeddings, GPT would just see numbers instead of meaningful language.
