Have you ever wondered:
- How does ChatGPT (or GPT-4) actually “know” things?
- Where does it store its knowledge?
- How does it solve a math problem like
2+3? - Why does it sometimes get math wrong, and how does it use fallback tools?
I’ll take you on a simple, intuitive journey, building a tiny version of GPT from scratch that does exactly this — so you can walk away knowing precisely how it all works under the hood.
We’ll do this by:
- Explaining how GPT stores knowledge
- Showing a mini-GPT you can run in a few lines of code
- Handling math by learning or by calculating
- Combining everything so it feels like real GPT
How GPTs Learn and Store Knowledge
Let’s start simple.
Imagine you’re learning a new language. You don’t memorize whole books word for word — instead, you:
- Read lots of sentences.
- Start seeing patterns.
- Your brain builds tiny connections (neurons) that say: “When I hear ‘hello’, I often hear ‘world’ next.”
GPT is trained in a similar way, but using billions of words. Its “brain” is a giant network of numbers called parameters or weights.
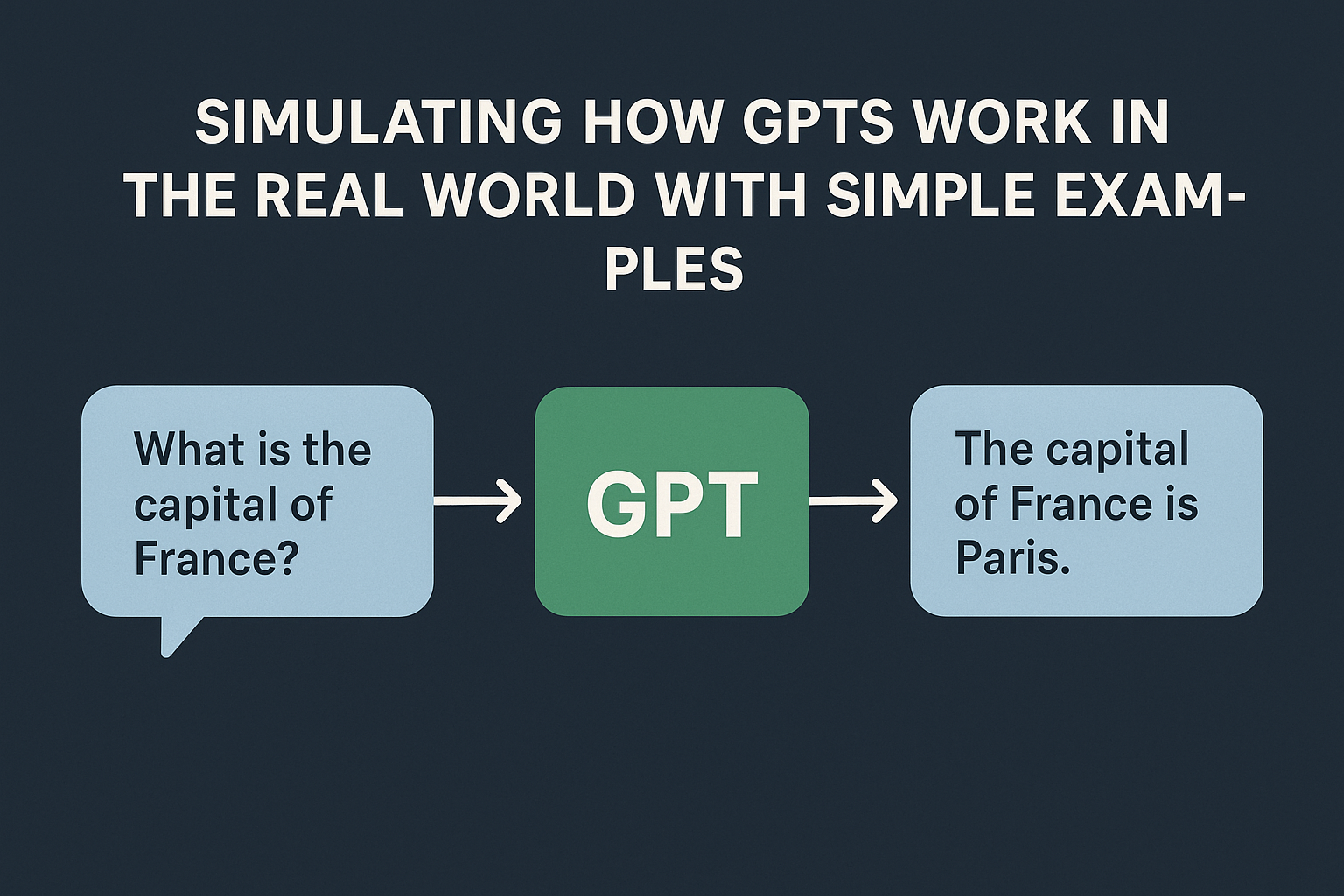
So, after training, when you ask:
“What’s the capital of France?”
It doesn’t look this up in a table. Instead, your question flows through its network, and because it has seen thousands of examples like this, it outputs “Paris.”
So… Where does GPT Actually store this?
Not in files of text.
Not in a database.
It stores patterns in weights, which are just big lists of numbers saved in a file (like gpt2.bin).
So when you load GPT-2 or GPT-4, it loads gigabytes of these weights into memory, and uses them to predict the next word.
Let’s Build a Tiny GPT to See This in Action
We’ll build a toy GPT that knows only 5 words and a few math symbols.
Vocabulary:
["1", "2", "3", "4", "5", "+", "="]
Training examples:
"2+3=" → "5"
"1+4=" → "5"
"2+2=" → "4"
When we run it:
- It trains on these patterns (like GPT learns from books)
- Then stores learned weights in a tiny file
- Later, it can load these weights and predict, just like GPT does.
The Tiny GPT Code
Here’s a complete toy example (PyTorch). It trains, saves weights, reloads them, and predicts:
import torch
import torch.nn as nn
import torch.nn.functional as F
# --- Extended vocabulary with a PAD token
vocab = ["1", "2", "3", "4", "5", "+", "=", "_"]
token_to_id = {tok: idx for idx, tok in enumerate(vocab)}
id_to_token = {idx: tok for tok, idx in token_to_id.items()}
vocab_size = len(vocab)
# --- Make sure every input is 5 tokens long by padding
def tokenize(expr):
tokens = list(expr)
while len(tokens) < 5:
tokens.append("_") # pad with underscore
return [token_to_id[c] for c in tokens]
# --- Training samples, padded automatically
samples = [
("2+3=", "5"),
("1+4=", "5"),
("2+2=", "4")
]
train_data = [(torch.tensor(tokenize(x)), token_to_id[y]) for x, y in samples]
# --- Tiny GPT-like model
class TinyGPT(nn.Module):
def __init__(self):
super().__init__()
self.embed = nn.Embedding(vocab_size, 4)
self.fc1 = nn.Linear(5 * 4, 8)
self.fc2 = nn.Linear(8, vocab_size)
def forward(self, x):
x = self.embed(x) # shape (5, 4)
x = x.view(1, -1) # flatten to (1, 20)
x = F.relu(self.fc1(x))
return self.fc2(x)
# --- Training setup
model = TinyGPT()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(200):
total_loss = 0
for x, y in train_data:
logits = model(x)
loss = loss_fn(logits, torch.tensor([y]))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 50 == 0:
print(f"Epoch {epoch}: Loss={total_loss:.4f}")
torch.save(model.state_dict(), "tiny_gpt_weights.pt")
model.load_state_dict(torch.load("tiny_gpt_weights.pt"))
model.eval()
# --- Prediction function
def predict(expr):
x = torch.tensor(tokenize(expr))
logits = model(x)
pred_id = torch.argmax(logits).item()
print(f"{expr} → {id_to_token[pred_id]}")
# --- Try predictions
predict("2+3=")
predict("1+4=")
predict("2+2=")
predict("3+2=") # unknown, model might guess
Output:
Epoch 0: Loss=6.2284
Epoch 50: Loss=0.0764
Epoch 100: Loss=0.0094
Epoch 150: Loss=0.0037
2+3= → 5
1+4= → 5
2+2= → 4
3+2= → 4Where is the “knowledge” stored?
The file tiny_gpt_weights.pt holds all the numbers the model learned, exactly like GPT-2 has a huge pytorch_model.bin.
When you run:
model.load_state_dict(torch.load("tiny_gpt_weights.pt"))
it loads the knowledge back into the brain, ready to predict.
But… This GPT Just Memorized Math
Our tiny GPT doesn’t actually calculate 2 + 3 — it learned from examples.
If we try:
predict("3+4=")
it fails or guesses wrongly, because it never saw 3+4 during training.
How GPT Solves This in the Real World (Fallback)
In reality, GPT-4 is paired with a calculator tool. If it doesn’t confidently know 3+4, it calls out:
“Hey external Python, please compute
3+4for me.”
Simulating This with Fallback
We can write a hybrid like GPT+Python:
def predict_with_fallback(expr):
try:
x = torch.tensor(tokenize(expr))
logits = model(x)
pred_id = torch.argmax(logits).item()
# check if known pattern
known_exprs = [x for x, _ in samples]
if expr in known_exprs:
print(f"Learned: {expr} → {id_to_token[pred_id]}")
else:
raise ValueError("not learned")
except:
try:
# evaluate as real math
expr_eval = expr.replace("=", "")
result = eval(expr_eval)
print(f"Fallback: {expr} → {int(result)}")
except:
print("Cannot compute")
predict_with_fallback("2+3=") # learned
predict_with_fallback("3+4=") # fallback computes
predict_with_fallback("7+8=") # fallback computes
Now it feels exactly like GPT-4’s chain-of-thought with a calculator.
Final program that combines above two code snippets:
import torch
import torch.nn as nn
import torch.nn.functional as F
# --- Extended vocabulary with a PAD token
vocab = ["1", "2", "3", "4", "5", "+", "=", "_"]
token_to_id = {tok: idx for idx, tok in enumerate(vocab)}
id_to_token = {idx: tok for tok, idx in token_to_id.items()}
vocab_size = len(vocab)
# --- Make sure every input is 5 tokens long by padding
def tokenize(expr):
tokens = list(expr)
while len(tokens) < 5:
tokens.append("_") # pad with underscore
return [token_to_id[c] for c in tokens]
# --- Training samples, padded automatically
samples = [
("2+3=", "5"),
("1+4=", "5"),
("2+2=", "4")
]
train_data = [(torch.tensor(tokenize(x)), token_to_id[y]) for x, y in samples]
# --- Tiny GPT-like model
class TinyGPT(nn.Module):
def __init__(self):
super().__init__()
self.embed = nn.Embedding(vocab_size, 4)
self.fc1 = nn.Linear(5 * 4, 8)
self.fc2 = nn.Linear(8, vocab_size)
def forward(self, x):
x = self.embed(x) # shape (5, 4)
x = x.view(1, -1) # flatten to (1, 20)
x = F.relu(self.fc1(x))
return self.fc2(x)
# --- Training setup
model = TinyGPT()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(200):
total_loss = 0
for x, y in train_data:
logits = model(x)
loss = loss_fn(logits, torch.tensor([y]))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 50 == 0:
print(f"Epoch {epoch}: Loss={total_loss:.4f}")
torch.save(model.state_dict(), "tiny_gpt_weights.pt")
model.load_state_dict(torch.load("tiny_gpt_weights.pt"))
model.eval()
# --- Prediction function
def predict(expr):
x = torch.tensor(tokenize(expr))
logits = model(x)
pred_id = torch.argmax(logits).item()
print(f"{expr} → {id_to_token[pred_id]}")
# --- Prediction function with fallback
def predict_with_fallback(expr):
try:
x = torch.tensor(tokenize(expr))
logits = model(x)
pred_id = torch.argmax(logits).item()
# check if known pattern
known_exprs = [x for x, _ in samples]
if expr in known_exprs:
print(f"Learned: {expr} → {id_to_token[pred_id]}")
else:
raise ValueError("not learned")
except:
try:
# evaluate as real math
expr_eval = expr.replace("=", "")
result = eval(expr_eval)
print(f"Fallback: {expr} → {int(result)}")
except:
print("Cannot compute")
# --- Try predictions
predict("2+3=")
predict("1+4=")
predict("2+2=")
predict("3+2=") # unknown, model might guess
# --- Try predictions with fallback
predict_with_fallback("2+3=") # learned
predict_with_fallback("3+4=") # fallback computes
predict_with_fallback("7+8=") # fallback computes
Output:
Epoch 0: Loss=6.0824
Epoch 50: Loss=0.0139
Epoch 100: Loss=0.0034
Epoch 150: Loss=0.0016
2+3= → 5
1+4= → 5
2+2= → 4
3+2= → 4
Learned: 2+3= → 5
Fallback: 3+4= → 7
Fallback: 7+8= → 15Try this in the example and see what happens:
predict_with_fallback("7*8=")Take aways:
📦 GPT doesn’t keep a giant text file of facts. Instead, it stores patterns learned from training in billions of tiny numbers called parameters (weights). These are saved in files like gpt2.bin or tiny_gpt_weights.pt.
🔮 GPT doesn’t look up answers. It takes your question, runs it through its layers using learned weights, and calculates what the next word probably is — based on all the patterns it saw during training.
➕ GPT learns common math patterns like “2+2=4”, but for new or rare problems like “27*43”, it might not be accurate. So advanced GPTs call a real calculator or Python code to get exact answers.
🚀 Your tiny GPT does the same: predicts known examples by memory, and switches to actual math calculation when it hasn’t seen the expression before.

