Large Language Models (LLMs) like GPT-4, or open-source models such as Mistral, have unlocked incredible ways to generate text, solve problems, and even reason with complex queries. But to make use of their true power, we need to learn the art of prompt engineering. In this post, I will go through: Thanks to Hugging Face’s …
Month: July 2025
The loss function is how LLMs learn in the first place At the heart of every machine learning model, from simple linear regression to massive LLMs like GPT-4, is a loss function.It measures how wrong the model’s predictions are. For language models, the most common loss function is cross-entropy loss, which measures how well the model’s predicted probability distribution …
How does a machine learning model know that if it is performing well or not? It needs a way to measure how far off its predictions are from reality. That’s where the loss function comes in. Think of the loss function as the model’s internal GPS telling it, “You’re this far away from your destination—time to adjust!” Simple …
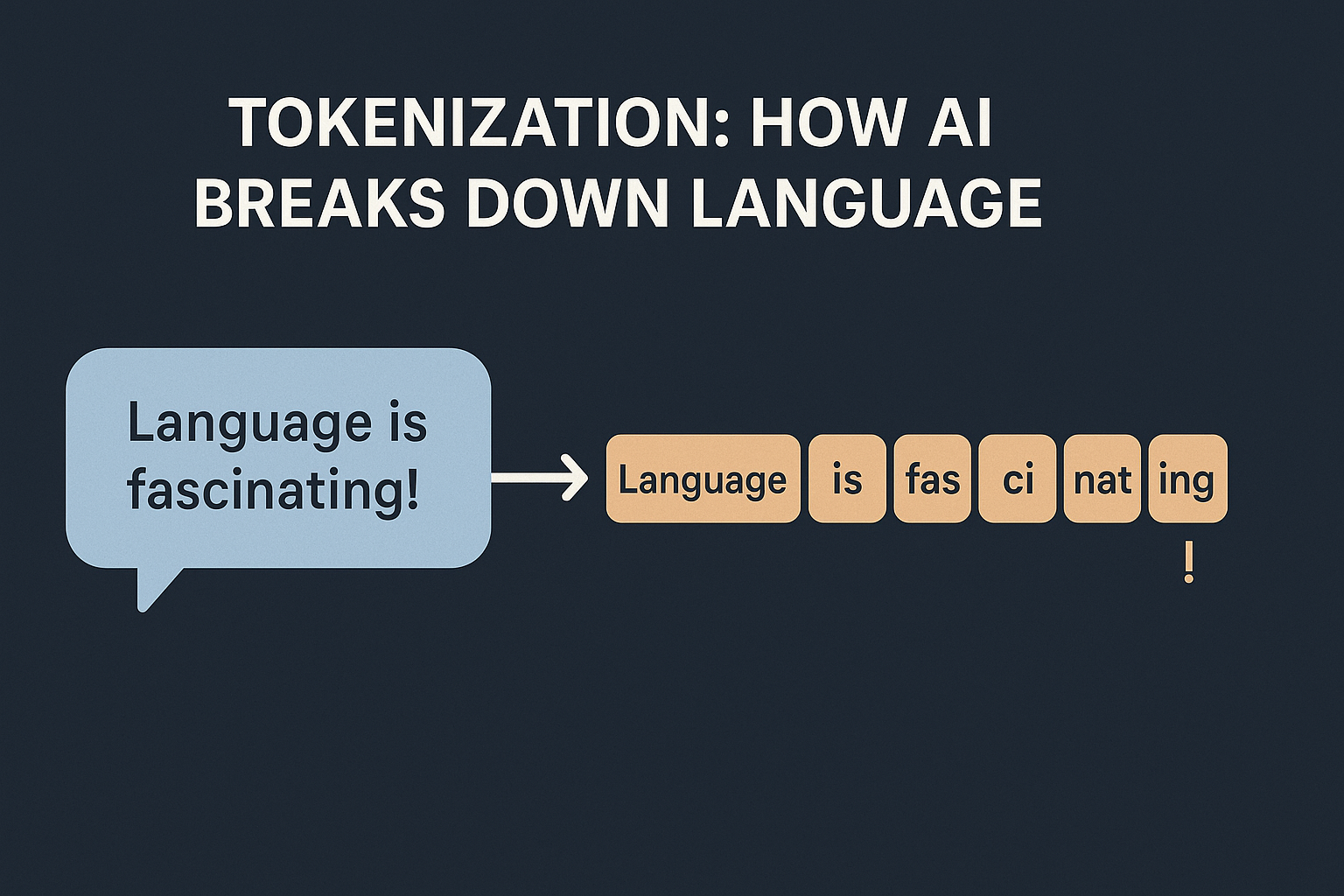
I am assuming the audience for this blog is programmers who may or may not have exposure to AI. Whenever we discuss about LLMs, we often hear the term “Tokenization“. In AI, it simply means how models break text into smaller pieces. Why can’t we just feed text to an AI? Machines don’t work with …